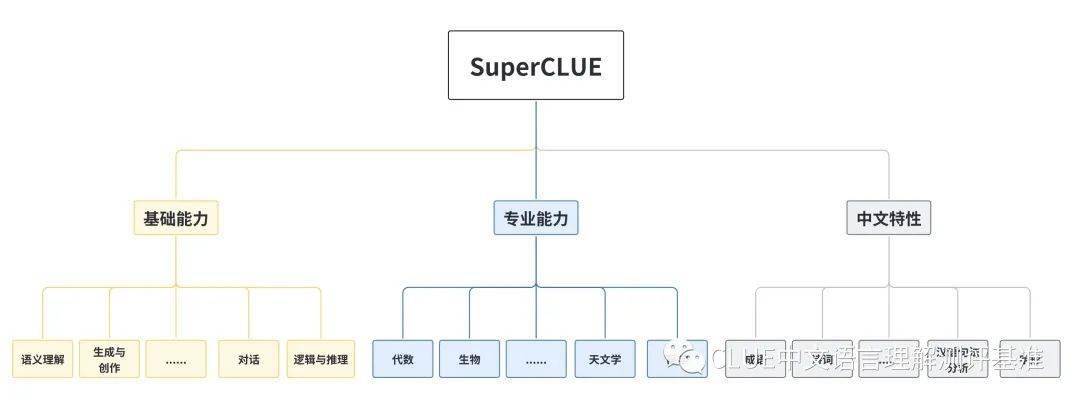
该模型可通过多个层面,考研市面上主流的中文 GPT 大模型的能力:
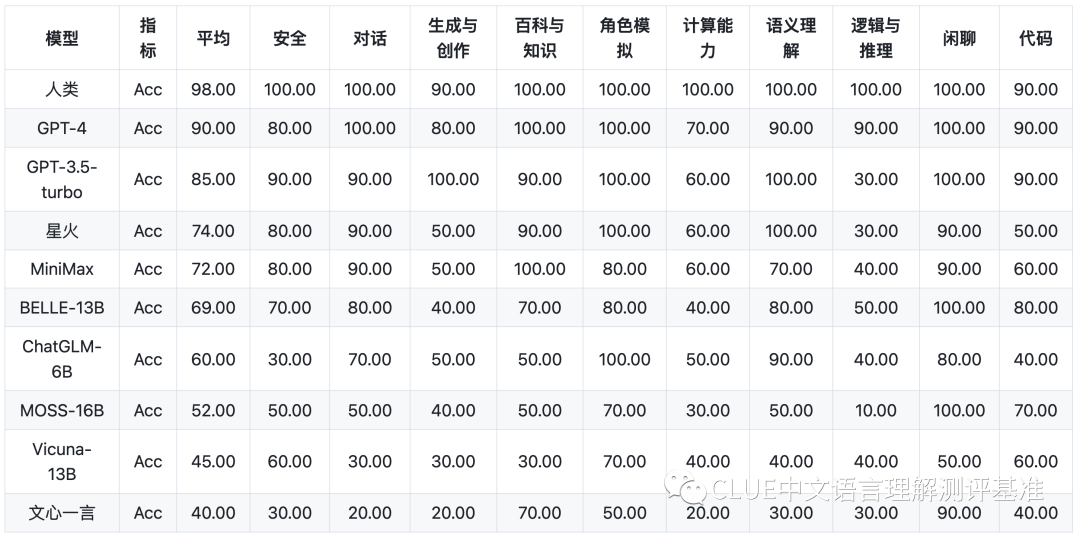
基础能力: 包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等 10 项能力。
专业能力: 包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等 50 多项能力。
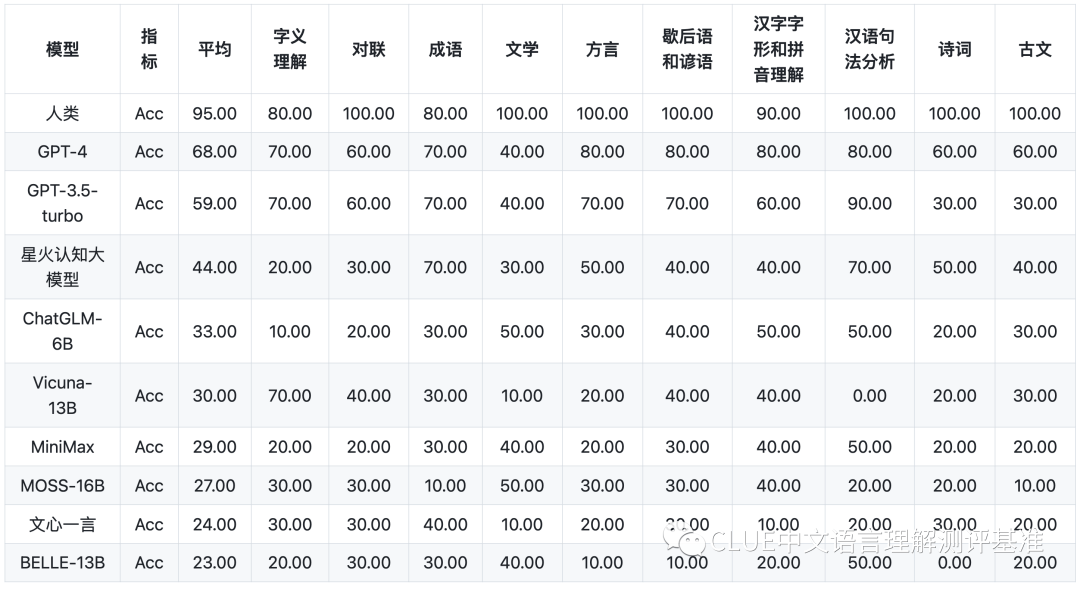
中文特性能力: 针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等 10 项多种能力。
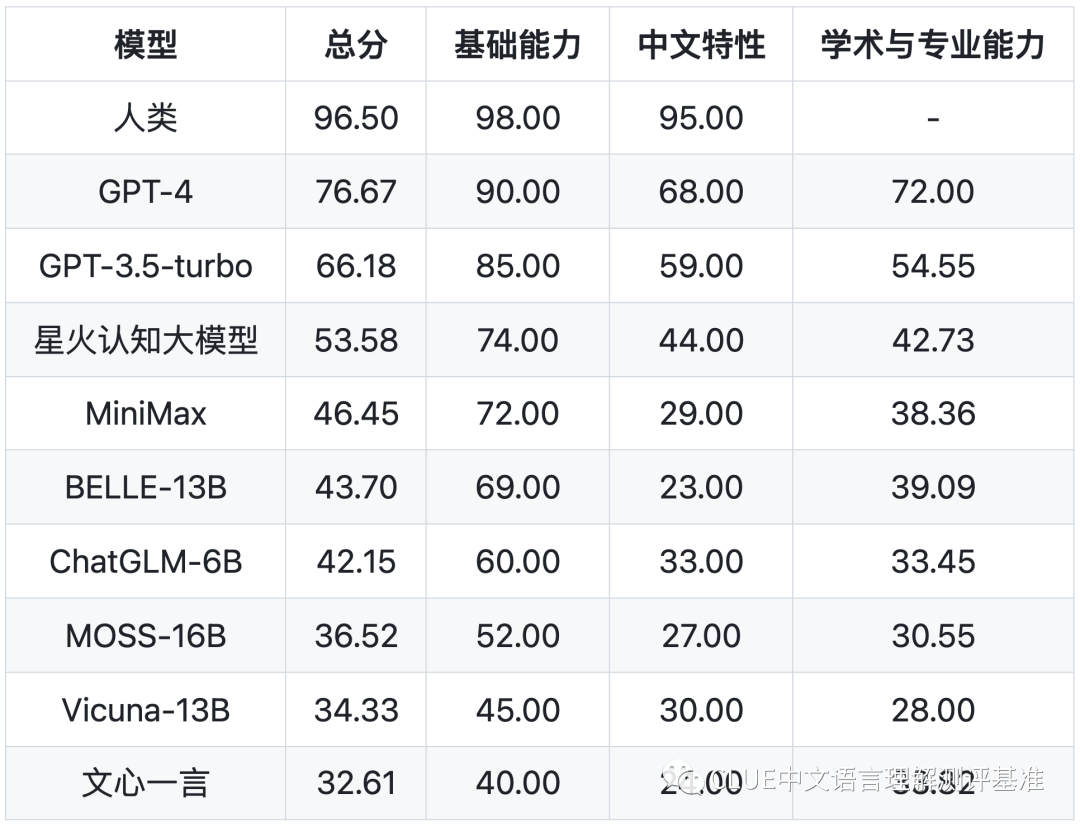
该机构利用 SuperCLUE 测试基准,对市面上主流的支持中文的通用大模型进行了评测与排名。从排名中我们可以看出,GPT-4 一骑绝尘,已经非常接近人类的能力。国产大模型中讯飞科技研发的星火认知大模型总排名第三,国内排名第一。
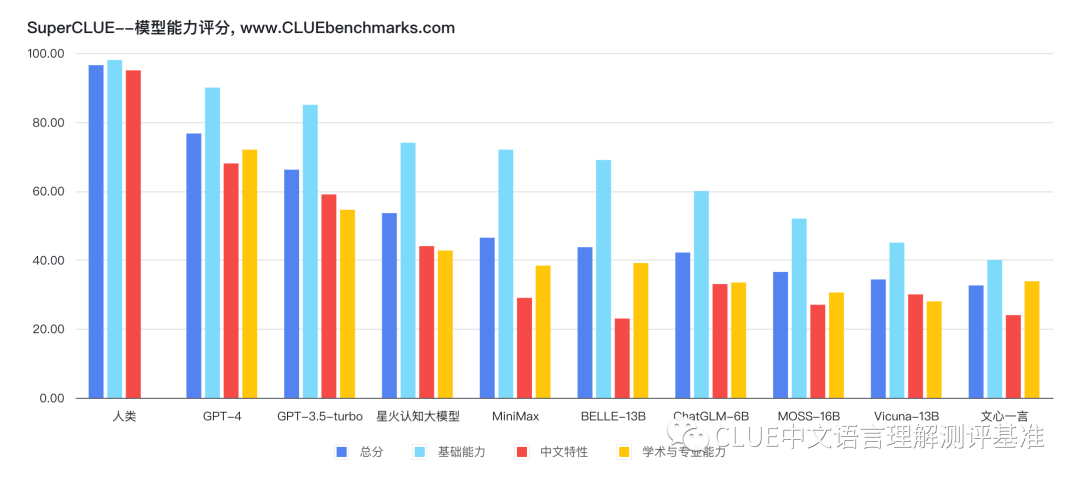
以下为该机构公布的各个子项目的具体得分。排行榜会定期更新,并于以下网站进行公示。CLUEbenchmarks 官方网站